Random Variables
In order to carry out a Probabilistic analysis with SWedge, you must define at least one input parameter as a random variable.
To define an input parameter as a random variable, select a statistical distribution for the variable (e.g. Normal, Uniform etc), and enter the required statistical parameters (e.g. mean, standard deviation, minimum and maximum values).
The following input parameters can be defined as random variables in an SWedge probabilistic analysis:
- Slope plane orientation
- Joint orientation
- joint shear strength
- Joint waviness angle
- Tension crack orientation
- Water pressure force
- Seismic force
In addition, if you are using the Joint Persistence Analysis option, you can define the following random variables:
- Wedge height
- Joint persistence or trace length
See the Joint Persistence Analysis topic for more information.
For information about the selection of statistical distributions, standard deviation and minimum/maximum values, see the Statistical Distributions Overview topic.
How Are the Random Variables Used in the Analysis?
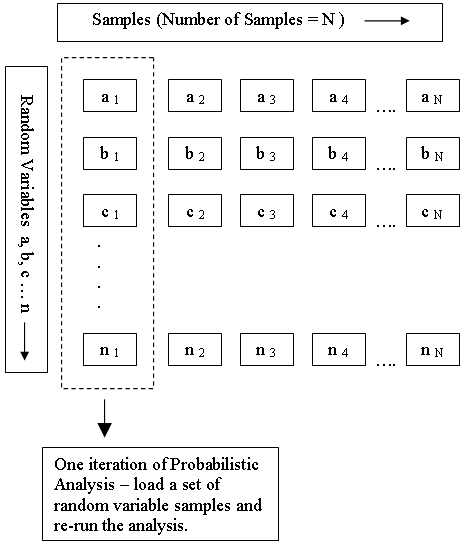
Each input parameter that is defined as a random variable, is sampled according to the statistical distribution you have defined for the variable, the Sampling Method and the Number of Samples (chosen in Project Settings). This generates N values of each random variable (where N = Number of Samples).
As shown in the following diagram, each iteration of the Probabilistic Analysis is carried out by loading a new set of random variable samples and re-running the analysis. This is repeated N times where N = Number of Samples.
Random Variable Samples used in Probabilistic Analysis
To carry out a Probabilistic Analysis, at least one input parameter must be defined as random.